La inteligencia artificial (IA) está destinada a minimizar el proceso de aprendizaje humano. La IA mejorará la práctica médica en gastroenterología en áreas que van desde la interpretación de imágenes y toma de decisiones.
Concepto de Inteligencia:
No existe una definición universal de la inteligencia y existen diferentes tipos de inteligencia. El concepto implica programas de computación que llevan a cabo funciones que se asocian con la inteligencia humana como el aprendizaje y la resolución de problemas. La inteligencia artificial (IA), el machine learning (ML) y el deep learning (DL) son disciplinas que se entremezclan.
Es la capacidad mental general que, entre otras cosas, compromete la habilidad de cada persona para razonar, planificar, resolver, pensar de manera abstracta, comprender ideas complejas, aprender con rapidez y aprender de la experiencia. Prof. Linda Gottfredson
Inteligencia es pensar, percibir, actuar…
Es la habilidad para conseguir objetivos complejos
La inteligencia implica ciertas actividades mentales como:
- Aprendizaje: es la habilidad para obtener y procesar nueva información
- Razonamiento: es la capacidad de manipular información de diferentes maneras
- Comprensión o entendimiento: es como se considera el resultado de manipular la información
- Establecer relaciones: determinar cómo los datos validados interactúan con otros datos
- Separar los hechos de las creencias
A pesar de que podemos crear algoritmos y acceder a datos para ser procesados por la computadora, la capacidad para que una computadora sea inteligente es muy limitada. Es muy difícil que una computadora pueda separar la realidad de lo irreal.
Los humanos no tenemos un solo tipo de inteligencia sino inteligencias múltiples que nos permiten llevar a cabo diferentes tipos de actividades (Howard Gardner)
Comencemos definiendo que no es Inteligencia Artificial (IA):
- Un robot no es IA, un robot es un contenedor de IA, es la computadora dentro del robot (la IA es el cerebro, el robot es el cuerpo). Esta interpretación de lo que la IA puede lograr se basa en lo que una gran cantidad de libros, películas y medios de comunicación crean esas expectativas en las personas.
La IA es la teoría y el desarrollo de sistemas de computación capaces de desarrollar actividades que requieren inteligencia humana como el reconocimiento visual, reconocimiento de la voz, toma de decisiones y traducir idiomas.
La IA es cualquier técnica que permite a las computadoras imitar el comportamiento humano
Heurística:
La heurística es el conjunto de tecnicas o metodos para resolver un problema, por ejemplo la regla de oro que nos orienta a una dirección con el objetivo de obtener el resultado deseado pero no dice exactamente cómo alcanzarlo. Es el caso de cuando alguien está perdido en una ciudad y recibe cierta orientación de donde queda el hotel donde se está hospedando. La clave es definir el procedimiento adecuado:
- Comenzar con una situación existente (puede ser la situación presente o una situación aleatoria conocida)
- Buscar un conjunto de posibles soluciones nuevas con las soluciones actuales en el vecindario,constituye la lista de candidatos
- Determinar cuál es la solución para usar en lugar de la solución actual basados en el OUTPUT de un heurístico que acepta la lista del candidato como INPUT
- Continuar pasos 2 y 3 hasta que no se aprecie mejora en la solución (mejor solución posible)
El espacio de estados es un proceso en el campo de la informática, incluyendo la inteligencia artificial, en el cual se consideran sucesivos estados de una instancia, con la meta de encontrar un estado final con las características deseadas.
La heurística son atajos mentales que se utilizan para resolver problemas comunes. Aceleran los procesos mentales pero a veces la velocidad hace que podamos obviar lo importante. Cuando funcionan son muy útiles pero cuando no funcionan hacen que veamos las cosas más simples de lo que realmente son.
Inteligencia Artificial:
La IA no tiene que ver con la inteligencia humana, lo que hace es simularla. La simulación es la capacidad de predecir lo que es más probable que pase en una situación. Constituye la manera de asociar la búsqueda de un objetivo, el procesamiento de datos para lograr ese objetivo y el proceso de adquisición de datos para entender mejor ese objetivo. La IA se soporta en algoritmos (procedimientos,métodos,etc) que están creados específicamente para lograr estos objetivos. Existe una interfase entre buscar el objetivo, el procesar datos para lograr un determinado objetivo y la manera de adquirir esos datos, utilizarlos para entender el objetivo final. La IA se trata de representaciones para apoyar modelos de pensamientos, percepciones y acciones.
La IA es una rama de las ciencias de computación dedicada a la creación de sistemas que puedan ejecutar tareas que requieren clásicamente de la inteligencia humana
El principio Rumpelstiltskin o Enano Saltarín: al nombrar algo adquieres poder, es decir se tiene el poder de categorizar algo.
Si una máquina se comporta en todos los aspectos como inteligente, entonces debe ser inteligente
Alan Turing
Historia de la IA
La inteligencia artificial es un puente entre el arte y la ciencia
Pamela mccorduck
- 1950: fue uno de los años clave para el desarrollo del concepto de IA. Alan Turing exploró la posibilidad de crear máquinas que piensen y creo lo que se conoce como la Prueba de Turing que se utiliza para determinar si una computadora puede pensar de manera inteligente como el ser humano.
- 1951: Christopher Strachey escribió un programa para jugar ajedrez utilizando una computadora que representa la primera vez que se intenta desarrollar esta posibilidad.
- 1956: John McCarthy, en la conferencia de Dartmouth, describió por primera vez el término IA.
- 1959: primer laboratorio de IA en el Instituto Tecnológico de Massachussets.
- 1960: se introdujo el primer robot en la línea de ensamblaje de General Motors.
- 1997: Deep Blue desarrollada por IBM vence al campeón mundial de ajedrez Kasparov. Sin embargo esta computadora solo fue capaz de vencer al campeón de ajedrez a pesar de su impresionante hardware y software.
La IA actualmente tiene gran demanda debido a mayor poder computacional, gran cantidad de datos, mejores algoritmos (deep learning), inversiones de grandes compañías. Otro aspecto importante es la aparición de computación en la nube (cloud computing) que permite el uso de servidores remotos con fines informaticos.

Lo más importante para la IA son los datos…
Ley de Moore: aproximadamente cada 2 años se duplica el número de transistores en un microprocesador
Gordon Moore
Empresas que aplican IA en el área de salud: IBM
Hasta ahora la IA ha tenido éxito, hasta ahora, en hacer esencialmente cualquier cosa que requiera pensar pero ha fallado en hacer lo que las personas y los animales hacen sin pensar
Donald knuth
Aplicaciones en Gastroenterología
La medicina es la ciencia de la incertidumbre y el arte de la probabilidad
William Osler
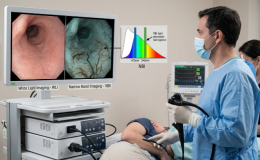
La endoscopia superior y la colonoscopia son los procedimientos más realizados por los gastroenterólogos, son operador dependiente. La endoscopia de alta calidad depende de ciertas variables como el tiempo empleado en el procedimiento, entrenamiento y la técnica del endoscopista para reconocer ciertas lesiones.
las dos áreas de mayor desarrollo de la IA son la detección asistida por ordenador (CADe) y el diagnóstico asistido por ordenador (CADx). La primera se encarga de desarrollar algoritmos para detectar patologías mientras que el segundo caso los algoritmos se dirigen a clasificar patologias (biopsia óptica y caracterización de lesiones).
Computer-aided detection (CADe):
- Se encuentra aprobada por la FDA para la detección de pólipos.
- Algoritmos de Machine learning aplicados para la detección primaria de condiciones patológicas como la detección de pólipos.
- Es el área más desarrollada en la aplicación de machine learning y deep learning en gastroenterología.
- Se aplica tanto en Endoscopia como en Colonoscopia.
Computer-aided diagnosis (CADx):
El CADx ha atraído mayor atención debido a su utilidad en la colonoscopia. Se ha demostrado que permite la clasificación de los pólipos de colon sin necesidad de tomar biopsia. El objetivo es realizar una biopsia óptica basada en la cantidad de estructuras superficiales que reflejan las características histológicas de la lesión.
- Se aplica para el diagnóstico de lesiones pre malignas del tracto digestivo como la displasia en el esofago de Barrett.
- Algoritmos de Machine learning aplicados a los datos médicos para predecir diagnósticos ( clasificación de pólipos) en lesiones neoplásicas o pre neoplásicas.
La IA puede ser de utilidad para la inspección total de la mucosa del tracto digestivo superior e inferior, nivel de limpieza de la colonoscopia o actividad de la enfermedad inflamatoria intestinal.
Se puede categorizar la IA de 4 maneras:
- Actuar de manera humana: para Turing, la IA existirá cuando cuando no seamos capaces de distinguir entre un ser humano y un programa de una computadora en una conversación a ciegas. Se puede utilizar en tecnologías como el procesamiento natural del lenguaje, representación del conocimiento, razonamiento automatizado y machine learning.
En el CAPTCHA (Completely Automated Public Turing Test to Tell Computers and Humans Apart) se aplica la prueba de Turing.
- Pensar de manera humana: cuando una computadora piensa como un humano, es capaz de realizar tareas que requieren inteligencia, como el hecho de conducir un vehículo. Para determinar si un programa puede pensar debemos contar con un método de como pensamos los humanos basados en un modelado cognitivo: introspección (técnicas para lograr objetivos), pruebas psicológicas (observar la conducta de las personas ya agregarla al banco de datos de conductas similares) y método de imagen del cerebro (monitorear la actividad cerebral por métodos de imagen)
- Pensar de manera racional: se estudia cómo piensa el ser humano para crear guías que permitan describir la conducta humana. El objetivo es resolver los problemas de forma lógica de ser posible.
- Actuar de manera racional: se estudia cómo los humanos actúan en situaciones determinadas y nos permite determinar que técnicas son más eficientes y efectivas.
Los procesos humanos difieren de los procesos racionales en su evolución. Un proceso es racional si siempre ejecuta una acción adecuada basado en la información actual (se asume que la información es correcta). Los procesos humanos incluyen instinto, intuición y otras variable y pueden no considerar la información previa.
Categorías de la IA:
- Inteligencia artificial limitada: es la IA que se especializa en una sola área. Por ejemplo existe un tipo de IA creada para derrotar al campeón mundial de ajedrez pero eso es lo único que hace, Alexa representa también un ejemplo de IA limitada. Se le conoce como IA débil.
- Inteligencia artificial general o IA a nivel humano: es la IA en la que la computadora es tan inteligente como el humano, es la que puede funcionar intelectualmente como el ser humano incluso el aprendizaje. Las máquinas no poseen actualmente las habilidades del ser humano. Se le conoce como IA fuerte y representa el holy grail para el desarrollo de la IA. Si le digo a la computadora que vaya al otro extremo de la habitación y encienda la luz eso no será posible a pesar de que puede realizar operaciones aritméticas complejas en cuestión de minutos.
- Superinteligencia artificial: se define superinteligencia aquella que es más inteligente que los mejores cerebros humanos en todos los campos incluyendo creatividad científica, conocimiento general y habilidades sociales.
El objetivo fundamental es construir inteligencia artificial general que sea capaz de manera virtual cualquier objetivo, incluyendo el de aprender.
Paradoja de Moravec: de forma antiintuitiva, el pensamiento razonado humano (el pensamiento inteligente y racional, requiere de poca computación, mientras que las habilidades sensoriales y motoras no conscientes y compartidas con muchos animales, requieren grandes esfuerzos computacionales
Hans Moravec
Un proceso es racional cuando siempre hace lo correcto basado en la información disponible, tomando en cuenta una medida de rendimiento que sea eficaz…

Aprendizaje de Máquinas (Machine Learning)
El término fue descrito por primera vez por Arthur Samuel en 1959. Es una tecnología que ayuda a las máquinas aprender de los datos, esto implica que no dependa de un programador para realizar operaciones sino derivarlos directamente a partir de ejemplos que muestran cómo la computadora debe comportarse. Es un conjunto de métodos computacionales que se basa en el uso de modelos matemáticos para aprender cómo capturar la estructura de los datos. Representa el estudio de algoritmos que mejoran con la experiencia. Cómo se produce gran cantidad de datos esta modalidad permite analizarlos con la finalidad de establecer modelos predictivos que tienen utilidad en muchos contextos. Las máquinas mejoran con la experiencia sin necesidad de algoritmos adicionales.
El ML puede actualmente alcanzar un nivel casi humano de aprendizaje en tareas específicas como es el caso de clasificación de imágenes y procesamiento de sonidos. El ML no está completamente automatizado ( no se le puede decir a una computadora que lea un libro y sepa todo su significado).
La inteligencia artificial y el machine learning no son lo mismo. La IA es un método que permite que las máquinas sean inteligentes y machine learning consiste en dar la capacidad a la maquina, posterior al ingreso de una gran cantidad de datos, pueda tomar sus propias decisiones. El machine learning se utiliza para tareas específicas mientras la IA es un término más general.
El machine learning no solo permite el análisis de grandes cantidades de datos, modelos predictivos sino también la resolución de problemas complejos.
La IA consiste en una serie de predicciones basadas en los patrones y otros factores utilizados para entrenar el software. Las predicciones son las que no permiten tomar decisiones bajo condiciones de poca certeza que es como nosotros como humanos funcionamos en la vida diaria y como los médicos toman la conducta adecuada para el paciente.
El ML es un conjunto de técnicas específicas que utilizan IA y son capaces de aprender a partir de patrones de modelos de datos utilizando funciones matemáticas. Esta fundación matemática se construye sobre los conceptos estadísticos tradicionales por lo que también se refiere a el término aprendizaje estadístico. El ML difiere de la estadística tradicional por su capacidad de utilizar operaciones matemáticas dimensionales con una mayor cantidad de datos para descifrar relaciones lineales complejas no lineales. Los algoritmos de ML han sido de utilidad en medicina para discriminar entre grupos de interés o predecir eventos específicos. Como ejemplos de modelos predictivos podemos nombrar el nomograma de Bhutani, el puntaje de enfermedad hepática terminal y el puntaje de Glasgow-Blatchford.
Es el campo de estudio que le da a las computadoras la habilidad de aprender sin ser explícitamente programadas
Arthur Samuel (1959)

Cómo aprendemos?
- Memorizando: acumular hechos individuales (tiempo y memoria para observar y memorizar): CONOCIMIENTO DECLARATIVO
- Generalizando: deducir nuevos hechos a partir de hechos viejos (se limita al proceso de deducción): CONOCIMIENTO IMPERATIVO
Algoritmo
Es una serie de reglas y técnicas estadísticas que se utilizan para aprender patrones de datos y obtener información de los mismos. Los algoritmos son secuencias de operaciones para encontrar soluciones a los problemas en un tiempo razonable. También puede definirse como una serie de instrucciones lógicas que muestran de principio a fin,como llevar a cabo una tarea. En realidad están formados por una secuencia de operaciones matemáticas (ecuaciones, álgebra,cálculo, lógica y probabilidad) que se expresan en códigos de computadora.
Un algoritmo es como un contenedor. Es una caja que almacena un método para resolver un tipo específico de problema. Los algoritmos procesan datos a través de una serie de estados previamente definidos
Existe un número incontable de algoritmos en la actualidad cada uno de los cuales tiene su propios objetivos, idiosincrasias, sus fortalezas y debilidades lo que hace difícil clasificarlos o agruparlos. Sin embargo los podemos clasificar en 4 categorías principales:
- Algoritmos de priorización (realizan listas ordenadas): ejemplo de estos algoritmos son el de Google que de prioridad de un resultado de búsqueda sobre otro y Netflix que sugiere que película te puede gustar la próxima vez. Todos utilizan procesos matemáticos para ordenar una gran cantidad de posibles opciones.
- Algoritmos de clasificación (escogen categorías): estos algoritmos son los preferidos por los comerciantes, lo que hacen es clasificar los intereses de la persona en base a sus características. Estos algoritmos pueden clasificar y eliminar contenido inapropiado de Youtube, clasificar tus fotografías y escanear tu manera de escribir para colocarles número a cada hoja.
- Algoritmos de asociación (encontrar relaciones o links): encuentran y crean relaciones entre cosas. Por ejemplo OKCupid busca conexiones entre personas para citas basados en aspectos comunes.
- Algoritmos de filtrado (separar lo que es importante): separan la señal del ruido. Ejemplo los algoritmos de reconocimiento de voz como SIRI, ALEXA y CORTANA.
La gran mayoría de los algoritmos están construidos para combinar estas categorías.
Un algoritmo es un procedimiento (secuencia de operaciones), usualmente relacionado con la computadora, que permite encontrar la solución correcta a un problema en un tiempo finito y puede predecir si realmente no existe solución a dicho problema
Existen 2 paradigmas en cuanto al uso de algoritmos:
Los algoritmos basados en reglas: sus instrucciones se construyen por un humano y son directas, sin posibilidades para la ambigüedad. Son similares a cuando se cocina siguiendo una receta o se toma una conducta médica en caso de una enfermedad particular. Sin embargo esto no implica que los algoritmos sean sencillos.
Los algoritmos basados en ML: se le proporciona a la computadora los datos, un objetivo y un feedback cuando esté en el camino correcto, se deja que trabaje por su cuenta para obtener el mejor resultado posible. Es algo parecido a como aprendemos los humanos.



Modelo
El modelo se entrena en base a los algoritmos utilizados en el machine learning.
Entrenamiento de Modelos
Los modelos se evalúan basados en su eficacia en la training data. Esta evaluación es muy similar a la métrica de bioestadística tradicional. Las métricas más comunes son la sensibilidad y el valor positivo predictivo. Visualmente un modelo se puede evaluar mediante curvas (estadística C).
Training data: es la utilizada para crear el modelo de machine learning que son esenciales para crear la salida o output.
Testing data: es la utilizada para evaluar qué tan efectivo es el modelo para predecir los resultados. Evalúa la eficiencia del modelo.
El proceso de entrenar un modelo de DL implica construir un algoritmo (algoritmo de aprendizaje) que pueda aprender de la training data. El término modelo se refiere al artefacto de modelo que es creado a partir del proceso de entrenamiento. Por esta razón la training data debe contener la respuesta correcta (objetivo o atributo del objetivo). El algoritmo de aprendizaje encuentra patrones en la training data que ayuda a realizar el mapeo de los datos (atributos) para lograr la respuesta.
La creación de modelos de ML se basa en optimizar las operaciones matemáticas aplicadas a los datos de entrada para obtener las respuestas más cercanas a lo posible o predicciones lo más cercanas a la realidad
Hiperparametros: todos los modelos de machine learning (ML) son regulados por lo que se conoce como hiperparametros que gobiernan la arquitectura del modelo y su proceso de entrenamiento. Como ejemplo de hiperparametros en redes neuronales son el número de capas y la tasa de aprendizaje. Otro ejemplo seria K-medias que es un método de agrupamiento que se utiliza en minería de datos. Estos parámetros no pueden generalmente ser optimizados durante el proceso de entrenamiento y se escogen basados en en número de ensayos.
Tipos de Hiperparametros: existen dos categorías de hiperparametros: los requeridos y los opcionales.
Hiperparametros requeridos:
- Número total de nodos input (todo input ya sea imágenes, texto o sonido se convierte en una valor numérico)
- Número total de capas ocultas
- Número total de nodos ocultos en capas ocultas
- Número total de nodos output
- Peso de los valores
- Desviación de los valores
- Tasa de aprendizaje
Hiperparametros opcionales:
- Horario de aprendizaje
- Dropout
- Tamaño mini-batch
Variables
Variables de respuesta:
Variables de predicción:
Datos
Solo se puede aplicar el ML si el análisis de los datos proporciona un input correcto. Es decir solo el ML puede asociar una serie de input y output, al igual que determinar las reglas de trabajo de una manera efectiva. El análisis de datos se concentra en entender y manipular los datos de manera que sean útiles, mientras que el ML se focaliza en tomar inputs de los datos y elaborar una representación interna que funcione para propositos practicos.
El objetivo principal del ML es representar la realidad a través de una función matemática que el algoritmo no conoce previamente pero que puede predecir después de analizar los datos. El aprendizaje en ML es matemático y termina asociando ciertos inputs con outputs. No tiene nada que ver lo que el algoritmo ha aprendido sino que el proceso de aprendizaje se describe training debido a que el organismo se entrena para obtener la respuesta correcta (output) a cada pregunta planteada (output).
Las técnicas de ML están diseñadas para entender y representar matemáticamente diferentes patrones representados en los datos. Por lo tanto la clave para el desarrollo de algoritmos adecuados se basa en la calidad y el tamaño de los datos utilizados.
Datos estructurados: en este caso la información ha sido guardada de una manera definida y organizada de manera que pueda ser indexada, referenciada y buscada de forma fácil y precisa. Generalmente los datos estructurados son cuantitativos y formados por valores numéricos,fechas o texto. Por ejemplo el caso de las historias médicas electrónicas tienen variables organizadas en un formato determinado.
Datos no estructurados: datos que no se ´pueden almacenar de una manera definida. La mayoría de los datos clínicos no tienen estructura: texto para documentación clínica, imágenes radiológicas, videos endoscópicos e informes escaneados. Generalmente este tipo de datos requieren extracción manual de la información.
Training data: es la utilizada para crear el modelo de machine learning que son esenciales para crear la salida o output.
Testing data: es la utilizada para evaluar qué tan efectivo es el modelo para predecir los resultados. Evalúa la eficiencia del modelo.
El ML difiere del modelo de programación tradicional en que la salida o output es un programa que se obtiene a traves del analisis de los datos estructurados y de la salida previamente obtenida.
Muchas personas piensan que las aplicaciones comienzan con una función, datos de input, para producir el output. Por ejemplo un programador puede crear una función que acepta varios valores y el resultado del proceso es el output. En el caso del ML el proceso es a la inversa, se tienen inputs y resultados, el problema es que no se sabe que función es la que produce el resultado deseado. No se sabe que funcion aplicar para obtener el resultado adecuado. El entrenamiento produce un algoritmo de aprendizaje en base a los inputs y los outputs obtenidos de estos inputs. Se utiliza el input para crear una función.
Existe un término matemático que se denomina mapping que ocurre cuando se descubre la construcción de una función observando los outputs.

Proceso
Se trata de construir un modelo predictivo.
- Definir el objetivo
- Recolectar datos: es un proceso que toma tiempo, existen herramientas en la Web que permiten la obtención de los datos de forma rápida y confiable ( Cargill)
- Preparar datos o limpiar datos
- Explorar datos: trata de conseguir patrones en el conjunto de datos, es una parte muy importante en machine learning
- Construir un modelo en base a training data (80%) y testing data (20%). Entre más datos en training data se supone que mejor es el testing data. Se definen las variables de acuerdo al tipo de datos y los resultados esperados.
- Evaluar y optimizar el modelo (testing data)
- Predecir: variables categóricas o variables continuas
Tipos de Machine Learning
El ML es la habilidad de aprender sin ser programado
- Aprendizaje supervisado: se enseña la máquina para utilizar datos que están bien categorizados (supervisión externa). Por ejemplo cuando los datos se categorizan en displásicos o no displásicos en el caso de los pólipos. Este tipo de aprendizaje ayuda a predecir las categorías basados en datos bien categorizados. Se utiliza en problemas tipo regresión o para clasificación de datos, amerita supervisión externa. El modelo es aportar datos (input) para obtener datos (output). Utiliza algoritmos tipo regresion lineal, regresion logistica, soporte de vectores,etc. Generalmente existe una menor cantidad de datos en comparación al aprendizaje no supervisado y se utiliza con mayor frecuencia en el área de la salud.
Ground truth: el outcome o la variable de salida que es utilizada para entrenar o para probar el modelo predictivo o la clasificación. Normalmente es la variable medida o una que haya sido previamente determinada por los expertos del dominio y es considerada la prueba de oro o el estándar de referencia
- Aprendizaje no supervisado: se enseña a la máquina a utilizar datos que no están bien categorizados lo que permite que el algoritmo actúe sobre esa información aportada sin ningún tipo de guia, por lo tanto no amerita supervisión. En base a la estructura de los datos se predice que datos son similares, puede ser útil cuando no se cuenta con un gold standard para una prueba determinada. El modelo se basa en entender patrones para descubrir output. Es decir que tiene que acceder a cientos de imágenes para descubrir ciertos patrones de los datos.Utiliza algoritmos tipo promedio-K, promedio-C. No utiliza el ground truth. Debe utilizar mayor cantidad de datos en comparación con el aprendizaje supervisado.
- Aprendizaje con reforzamiento: es muy diferente cuando se compara con el aprendizaje supervisado y no supervisado. En este caso un agente se pone en un ambiente y aprende a comportarse en este entorno, si obtiene recompensas esto hace que su aprendizaje se oriente a obtenerlas. No se utiliza datos para alimentar este tipo de aprendizaje, no existe supervisión. Sigue el modelo de ensayo y error. Utiliza algoritmos de Q-learning, SARSA. Este tipo de aprendizaje se utiliza en Alfago y Tesla.
En el aprendizaje supervisado se utilizan datos categorizados para obtener una salida o output conocido, en el aprendizaje no supervisado se trata de entender patrones para descubrir la salida o output

La capacidad para predecir e interpretar es importante para reconocer los algoritmos de uso más común en medicina. Los modelos supervisados que se utilizan para agrupar variables discretas que se conocen como clasificadores se utilizan para resolver problemas de clasificación. Si los resultados de la salida son mutuamente exclusivos a estos se les conoce como clases.
El DL es un tipo especial de acercamiento de ML que abarca los tres tipos de ML: aprendizaje supervisado, no supervisado y con reforzamiento
TIPOS DE PROBLEMAS EN MACHINE LEARNING
| REGRESIÓN | CLASIFICACIÓN | CLUSTERING |
| APRENDIZAJE SUPERVISADO | APRENDIZAJE SUPERVISADO | APRENDIZAJE NO SUPERVISADO |
| OUTPUT ES UNA VARIABLE CONTINUA | OUTPUT ES UNA VARIABLE CATEGÓRICA | SE AGRUPAN LOS DATOS |
| EL OBJETIVO ES PREDECIR | EL OBJETIVO ES CATEGORIZAR | EL OBJETIVO ES AGRUPAR |
| EJEMPLO: PREDECIR LA TEMPERATURA | EJEMPLO: PREDECIR SPAM | DETECTAR TRANSACCIONES FRAUDULENTAS |
| ALGORITMO: REGRESIÓN LINEAL | ALGORITMO: REGRESIÓN LOGÍSTICA | ALGORITMO: K-MEANS |
Los problemas de clasificación que incluyen las características clínicas son candidatos a modelos de regresión, soporte de vectores, árbol de decisiones y árboles aleatorios. Los problemas de clasificación más complejos como el procesamiento de imágenes requieren de métodos más sofisticados como las redes neuronales.
Es importante determinar cuál es el tipo de modelo a utilizar y cual es el beneficio clínico de utilizar un modelo en particular

Algoritmos Supervisados

- Regresión lineal: es un método para predecir una variable dependiente basado en los valores de variables independientes, se utiliza para predecir cantidades continuas. La variable dependiente (OUTPUT) es la variable cuyo valor requiere ser predecido, la variable independiente (INPUT) es la que se utiliza para predecir la variable dependiente.

- Regresión logística: es un método para predecir una variable dependiente (Y) basado en un conjunto de variables independientes, como es el caso de que la variable dependiente sea categórica (0 o 1, verdadero o falso). Pertenece a los modelos lineales y se utiliza en problemas de clasificación (algoritmo de clasificación)
- Árbol de toma de decisiones: es un algoritmo supervisado de ML que parece un árbol invertido, donde cada nodo representa una variable predictiva, el link entre cada nodo representa una decisión y cada nodo siguiente representa un pronóstico. Es un algoritmo de clasificación y predice un valor categórico.
Ejemplo:
El nodo raíz es el punto de inicio del árbol, es la variable más importante: Indicadores de Riesgo para Hemorragia Digestiva Inferior
El mejor atributo para el nodo raíz es aquel que es capaz de separar los datos en diferentes clases de manera más efectiva
Las raíces o conexiones son las comunicaciones entre los nodos, cada raíz representa una respuesta que puede ser SI o NO.
Los nodos internos representan puntos de toma de decisión (variable predictiva) que eventualmente lleva a la predicción del pronóstico: Paciente Estable o Inestable
Los nodos terminales representan la clase final de la predicción: Cirugía

- Bosque aleatorio
- Clasificador de Bayes
- Máquinas de soporte de vectores
Algoritmos no Supervisados


Deep Learning
Las neuronas artificiales han sido estudiadas desde los años 40 pero hace solo pocas décadas su interés ha ido en aumento debido al desarrollo de arquitecturas más avanzadas y el aumento del poder computacional. Se considera el DL es el nombre que se da a una clase específica de redes neurales (clase especial de algoritmos de ML) aplicable a procesamiento de lenguaje natural, visión de computadoras y robótica.
Esta arquitectura de redes neuronales se basa en el funcionamiento del cerebro humano y consiste en una capa inicial que recibe el input seguido de un número oculto de capas antes de producir el output. Cada capa consiste en un conjunto de neuronas artificiales o nodos que convierten un input en output utilizando funciones matemáticas específicas (como la regresión logística). El output de cada grupo neuronal se presenta al siguiente grupo como un input que genera otro output en forma sucesiva.
El DL extrae patrones de los datos utilizando redes neuronales
Las redes neuronales resuelven los problemas de una manera diferente a los programas de computación convencionales. Para resolver un problema la computadora utiliza un software convencional que se basa en una serie de algoritmos (sigue una serie de instrucciones predeterminadas). Las redes neuronales resuelven el problema de una manera diferente, es decir aprenden por ejemplo.

Es una tecnología que trata de imitar el cerebro humano utilizando redes neuronales con diferentes capas. Es una manera de extraer patrones de utilidad de los datos a través de la optimización de redes neuronales. Utiliza librerías y programas que permiten el desarrollo de una gran cantidad de aplicaciones (por ejemplo TensorFlow). Existen plataformas de deep learning muy interesantes como Gato de deepmind. En medicina se ha aplicado a un conjunto de problemas clínicos como la detección de cáncer de mama en la mamografia, diagnostico de cáncer de piel y retinopatía diabética. En el campo de la gastroenterología se aplica a un amplio rango de problemas clínicos y de interpretación de imágenes en el área de endoscopia. Las redes neuronales se pueden utilizar no solo para el reconocimiento de imágenes endoscópicas, sino también para oír, lenguaje (traducción), control (juegos de video).
Una red neuronal es un grupo de neuronas interconectadas que tienen la capacidad de tener influencia sobre el comportamiento de otras. La diferencia con el machine learning es que las características y las relaciones son aprendidas a partir de los datos disponibles.
Las redes neuronales son específicas: se construyen para resolver un tipo específico de problema, pero no quiere decir de que pueda ser utilizado para propósitos más generales. Se puede utilizar por ejemplo para el diagnóstico médico.
Las redes neuronales están constituidas por tres partes: capa de input, capa(s) oculta(s), capa de output. Cada parte está constituida por nodos.
Las redes neuronales están construidas de dos maneras: la primera en que las señales viajan en un solo sentido (input, output) y son utilizadas para reconocimiento de patrones (reconocimiento facial). Estos se denominan convolutional neural network (CNN o Convnet). En la segunda las señales pueden viajar en ambas direcciones y pueden existir loops (recurrent neural networks). En este caso las redes neuronales son más complejas,poderosas y pueden estar cambiando de manera frecuente, sin embargo sus algoritmos son menos poderosos cuando se comparan con el CNN. Los CNN tienen mayor similitud con el cerebro humano.
Las redes neuronales o son fijas o adaptativas: en el caso de las fijas los valores permanecen estables (no cambian). En el caso de las adaptativas los valores no permanecen estables (cambian).
Podemos imaginar una red neuronal como una estructura matemática enorme con una gran cantidad de nodos. Se puede alimentar con una imagen endoscópica en un extremo, esta imagen fluye a través de la estructura, en el otro extremo se determina que representa esta imagen. Se puede categorizar de una manera más o menos exacta. Al comienzo esta red neuronal es una estructura desorganizada, comienza sin ningún conocimiento ni idea de lo que se trata, todos los nodos están dispuestos de forma aleatoria, pero en la medida que se alimenta de datos se van entrenando. Después de cada predicción que se realiza en el network un conjunto de reglas matemáticas trabaja para ajustar todos los nodos hasta que la predicción se acerque a la respuesta correcta.
Lo sorprendente de las redes neuronales es que sus operadores normalmente no entienden cómo y por que el algoritmo llega a esas conclusiones. Este proceso es difícil de conceptualizar desde nuestro punto de vista.
Las redes neuronales utilizan 3 tipos de datos:
- Datos de entrenamiento: se utilizan para ajustar las variables (60%)
- Datos de validación: se utilizan para minimizar un problema conocido (20%)
- Datos de prueba: se utiliza para probar cómo se comporta el modelo (20%)


Se pueden llegar a simular hasta 4 billones de sinapsis y 16.7 millones de neuronas.
Neuronas artificiales:
Un perceptrón representa la red neuronal más sencilla. La idea de los perceptrones (los predecesores de las neuronas artificiales) es que es posible imitar ciertas partes de las neuronas (como las dendritas, axones y cuerpo) utilizando modelos matemáticos simplificados. Las señales pueden ser recibidas por las dendritas y transmitidas por los axones una vez que existan suficientes inputs, estos inputs pueden ser utilizados por otras neuronas repitiendo el proceso. Unas señales pueden ser más importantes que otras lo que hace que las neuronas transmiten más fácil. Un perceptrón multicapas es la red neuronal más sencilla y consiste en una capa input, una capa output y al menos una capa oculta. Cada perceptrón está totalmente conectado de manera que cada nodo de cada capa está conectado a cada nodo de la próxima capa. Cada una de estas conexiones indica un parámetro que puede ser entrenado y optimizado.
El cerebro tiene 100 billones de neuronas y 1000 trillones de sinapsis. La red neuronal tiene 60 millones de sinapsis. El cerebro humano tiene 10000000 más de sinapsis que una red neuronal.
El cerebro humano no tiene capas y trabaja de manera asincrónica.
Se desconoce al algoritmo de aprendizaje que utiliza el cerebro y nunca termina de aprender.

Las redes neuronales aprenden por ejemplo no por estar programadas para una tarea específica
La propiedad única de las redes neuronales es que pueden utilizar, si están bien configurados, cualquier función matemática. Esto permite utilizar datos estructurados y no estructurados, aprendizaje supervisado y no supervisado. Están compuestas por una gran cantidad de elementos interconectados (nodos) que trabajan en paralelo para resolver un problema específico.
Una red neuronal hace el cómputo en función de INPUTS que propagan valores de estas neuronas al OUTPUT, se utilizan ciertos parámetros intermedios. El aprendizaje ocurre cambiando el peso de las neuronas interconectadas. Al igual que los estímulos externos se necesitan para el aprendizaje de los organismos biológicos, el estímulo externo en las redes neuronales proviene de la training data que contiene ejemplos de pares de INPUT-OUTPUT de la función que requiere ser aprendida. Por ejemplo el caso de training data que contenga representaciones de píxeles de imágenes (INPUTS) y sus categorías anotadas (cambur) que representa el OUTPUT. Estos datos alimentan la red neuronal con la finalidad de hacer predicciones(OUTPUT).
INPUT
Todo Input es la primera capa de una red neuronal, representa una dimensión simple o característica que es almacenada en un vector. Por ejemplo si se tiene una imagen de 16×16 píxeles como input esto representa un total de 256 nodos de input. Esto se explica porque cada nodo representa un solo pixel y hay 256 píxeles en total.
CAPA OCULTA
Una capa oculta es una capa de nodos entre las capas de INPUT Y OUTPUT. Pueden existir una sola capa o múltiples capas y entre mas capas existan mucho mejor para el aprendizaje profundo. El término deep learning se refiere justo a mejorar el aprendizaje al mejorar el número de capas ocultas.
NODO OCULTO
Un nodo oculto es un nodo en una capa oculta. Una capa oculta puede contener múltiples nodos ocultos.
NODO OUTPUT
Un nodo output es un nodo en la capa OUTPUT, puede ser uno o varios nodos dependiendo del objetivo de la red.
Tanto el INPUT como el OUTPUT de una red son vectores

A un nivel elevado, las redes neuronales aprenden como nosotros lo hacemos, por ensayo y error. Eso es una realidad independientemente si es supervisado, no supervisado o semi supervisado. Las funciones matemáticas desempeñan un papel fundamental en el proceso de ensayo y error.
Visión de Computadora
- El 50% de nuestra actividad cerebral está relacionada con la visión.
- La visión binocular nos permite apreciar un objeto en 2D y también inferir en 3D
- La visión se ha desarrollado en nuestro planeta desde hace más de 500 años
- Leonardo Da Vinci fue el primero que describió los principios de la fotografía (cámara oscura)